Biologically Inspired Speech Recognition Models
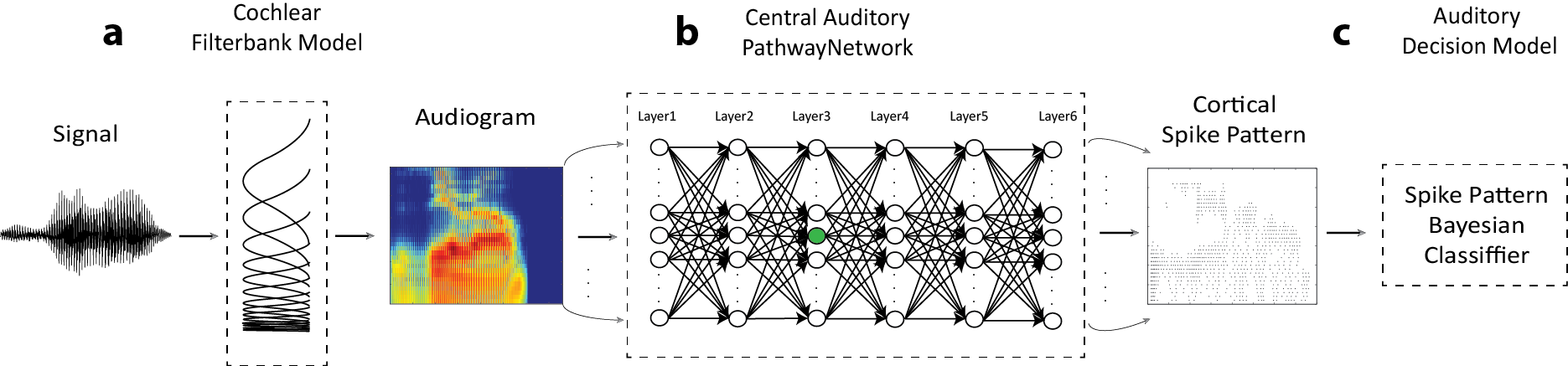 Mammalian audition is highly resilient to acoustic variability, such as background noise and multiple talkers, yet how the brain accomplishes this seemingly simple feat is unknown. One plausible hypothesis suggests that the ascending auditory pathway is organized into hierarchical processing stages with sequentially changing feature extraction capabilities that culminate in an invariant noise robust representation. We are currently developing biologically inspired speech and sound recognition models as illustrated above (Khatami & Escabi 2020), that 1) take into account hierarchical architecture of the ascending auditory pathway, 2) contain a variety of physiologically realistic mechanisms such as descending and ascending inhibitory projections. These models differ from conventional neural networks used in speech recognition as a result of their architecture and the fact that we make use of spiking neurons with realistic temporal dynamics. Using spike train outputs of this network we can accurately recognize speech even in the presence of background noise.
Mammalian audition is highly resilient to acoustic variability, such as background noise and multiple talkers, yet how the brain accomplishes this seemingly simple feat is unknown. One plausible hypothesis suggests that the ascending auditory pathway is organized into hierarchical processing stages with sequentially changing feature extraction capabilities that culminate in an invariant noise robust representation. We are currently developing biologically inspired speech and sound recognition models as illustrated above (Khatami & Escabi 2020), that 1) take into account hierarchical architecture of the ascending auditory pathway, 2) contain a variety of physiologically realistic mechanisms such as descending and ascending inhibitory projections. These models differ from conventional neural networks used in speech recognition as a result of their architecture and the fact that we make use of spiking neurons with realistic temporal dynamics. Using spike train outputs of this network we can accurately recognize speech even in the presence of background noise.
Optimal Models and Natural Sound Statistics
Horace Barlow (1961) was the first to propose that sensory systems might be optimized to efficiently encode natural environmental stimuli – thus potentially maximizing perceptual capabilities while minimizing metabolic demands. Below, is our two hierarchical auditory model inspired by well known auditory system transformations in the periphery and and feature extraction computations. Using a collection of environmental sounds, we have shown that the auditory system may be optimized for equalizing the power distribution of natural sounds at two levels. This processing strategy may improve the allocation of resources throughout the auditory pathway, while ensuring that a broad range of auditory features can be detected and perceived and may contribute to human perceptual abilities. We envision that adopting such processing strategies could enhance the performance of auditory prosthetics and machine systems for sound recognition.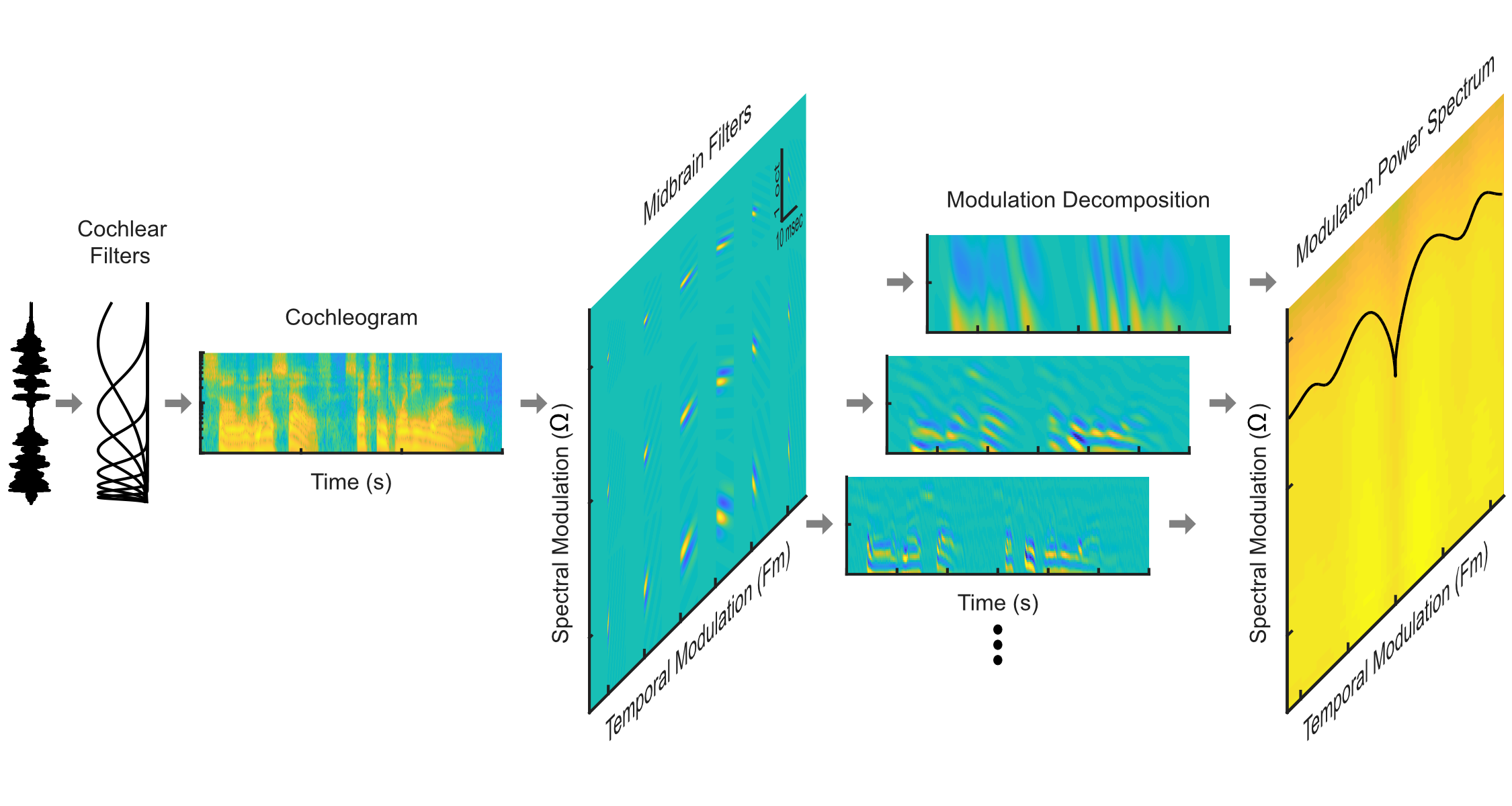
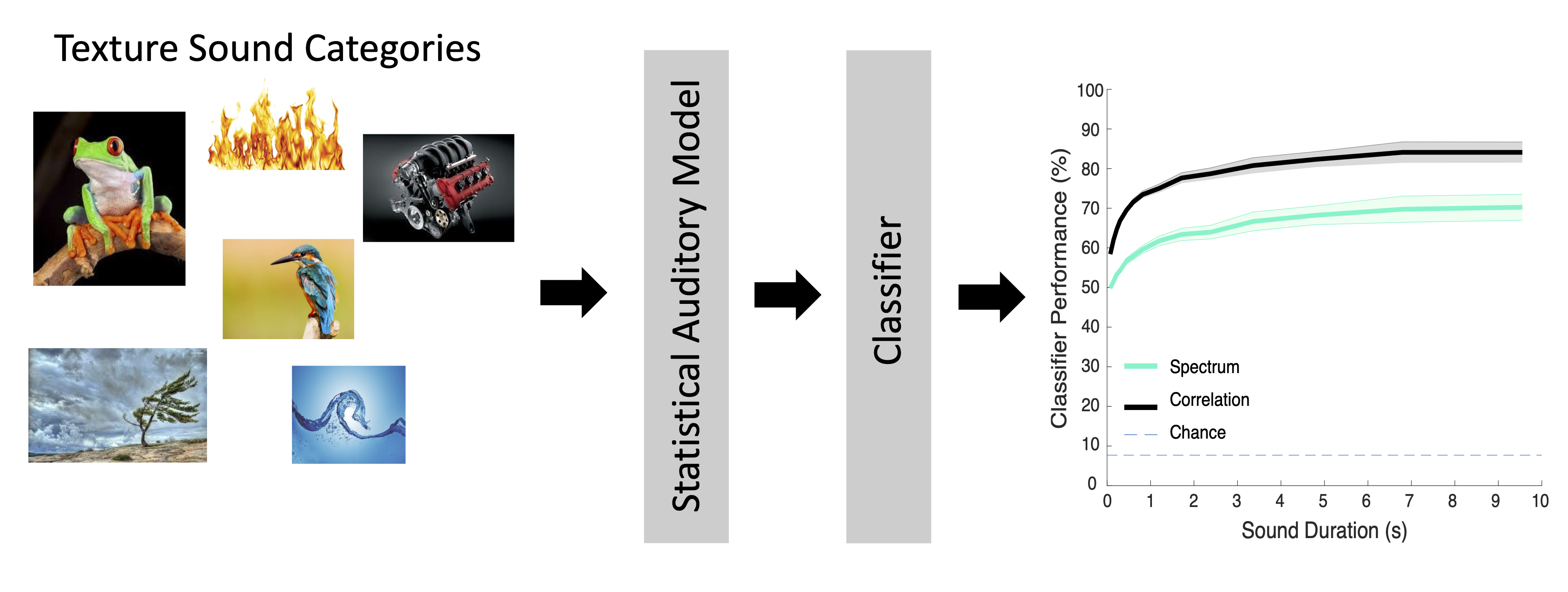
Environmental Sound Recognition and Sound Categorization
We’ve also developed models that can identify environmental sounds using biologically inspired sound processing principles. These models are designed to measure sound summary statistics that contribute to perception of sounds (McDermott and Simoncelli 2013) . Recently, we have shown that these summary statistics are present in the coordinated activity of neural ensembles (neural summary statistics). Below is an example multi-channel recording showing how neural activity in auditory midbrain can be used to categorize various speech, fire and a water sound recordings (Sadeghi et al 2019).
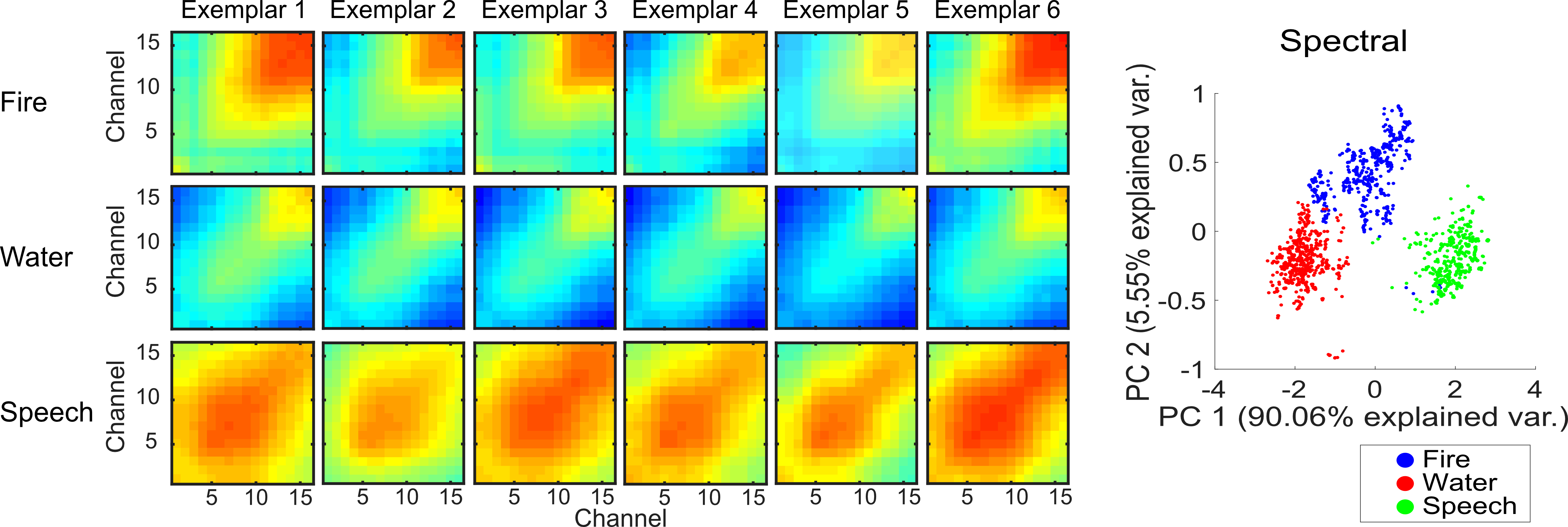
The dynamic output of our biologically inspired auditory model is shown below for a speech sound segment. The cochlear model spectrogram is shown on the top panel while the dynamic model output statistics are shown on the bottom panels.
Categorization results shown below illustrate that the model is able to accurately identify sound categories.