 |
Using high-order sound level statistics from an auditory model for sound category identification. |
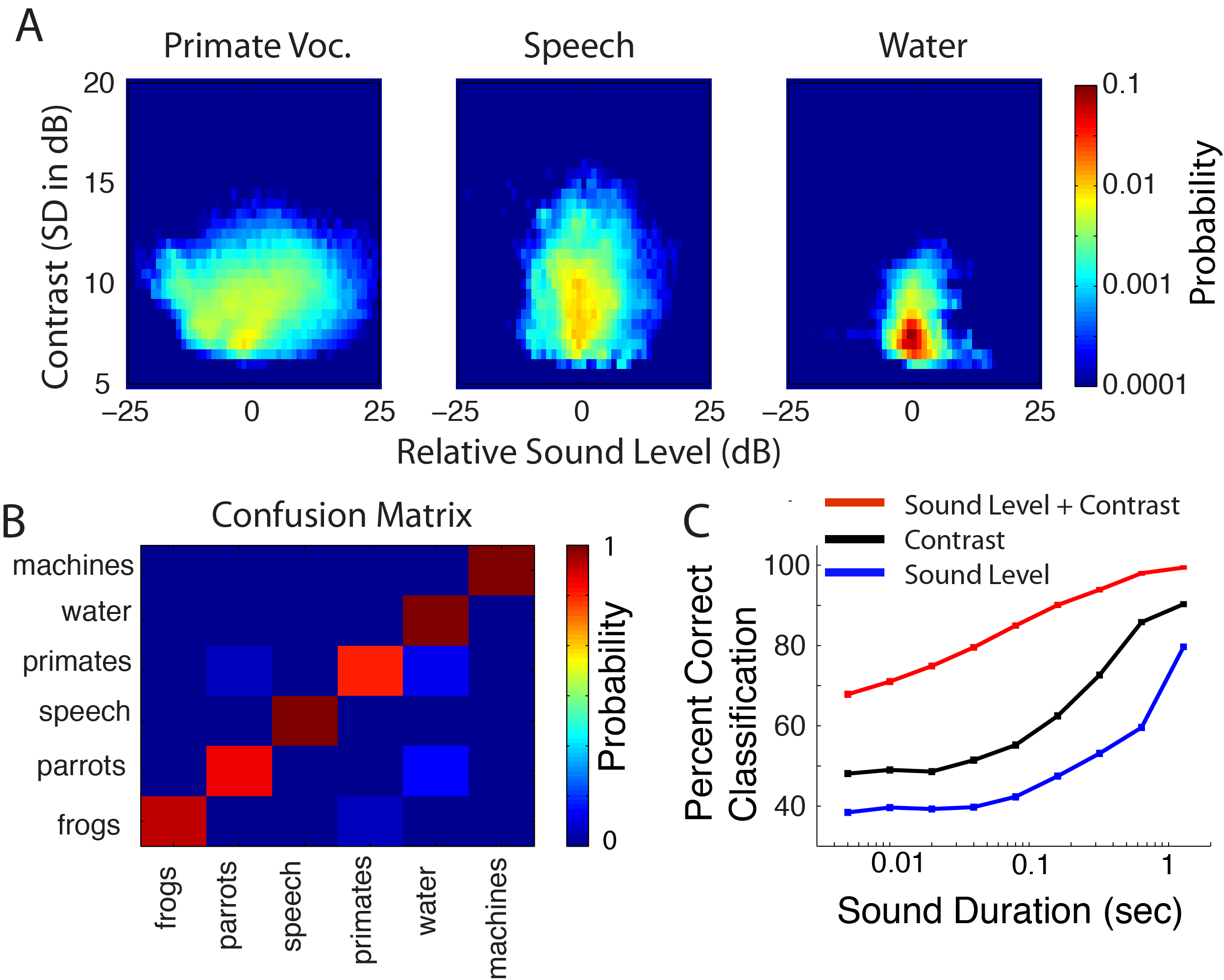
How do we recognize sounds and what are the neural computations required for successful sound recognition? For many sounds, such as speech, our brains can search for repeatable acoustic patterns to identify a word or a particular sound. Although there are acoustic differences from subject-to-subject for the word ‘hello’, different experts have a common phonetic structure and a reliable time-frequency composition. Theoretically, our brains can search for such repeatable acoustic patterns to carry out sound recognition.
Unlike speech, there area many sounds that lack a consistent and repeatable acoustic signature. We can easily identify and associate the sound of wind, running water, or busy intersection even though the acoustic waveforms from different exemplars are quite different and unique. How does the brain accomplish this task? We are currently exploring the role of statistical structure and its possible role for sound recognition. While two experts of water sounds are physically quite different, water sounds have relatively stable statistical characteristics, which could be used to identify and distinguish water from other sounds.
We have previously shown that neurons in the central nervous system are optimized to extract information from a variety of statistics found in natural sounds (Escabi et al 2003;Rodriguez et al 2010). Using large-scale neural recording arrays (Neuronexus) we are currently exploring how the brain of mammals extracts and utilizes high-order statistical regularities for sound recognition. We are also developing biological inspired models and sound recognition algorithms that utilize sound statistics. We hope to develop a comprehensive theory for how the central nervous system encodes and utilizes statistical structure in sounds while develop processing strategies for sound recognition, coding and compression, and to assist individuals with hearing loss.